

□研究紹介
目次
- 活動方針
- テーマ1: 仏典の情報処理
- テーマ2: 聖教と人間関係のデータベース
- テーマ3: 医療・介護の支援システム
- テーマ4: アンケートに対するデータマイニング
- テーマ5: 全文検索システム
- テーマ6: ソフトウェア理解支援
- テーマ7: 訓点資料の読解支援
- テーマ8: 系図データ処理
- テーマ9: 災害記事データベース
- テーマ10: 情報リテラシーの理解度テスト
- テーマ∞: その他のデータベースシステム
活動方針 [E]
キーワード:データエンジニアリング,データベースシステム,ウェブアプリケーション
私は,情報通信システム学科内で「データエンジニアリング研究グループ」の一員として,研究室の学部生・大学院生とともに,情報通信分野の教育および研究に取り組んでいます.
私の活動は主に,データベースシステムの設計・構築・運用です.研究課題ごとに,ユーザのニーズを反映させたシステムを創り上げます.学外の研究打ち合わせにもよく参加し,利用者の求めているものを聞き取るとともに,できあがったアプリケーションが期待通り動く喜びを,利用者と共有しています.
かつては「暗号プロトコルの安全性検証」という,情報セキュリティの分野の研究をしていました.「どのように対象を記述すれば,計算機で利用でき,かつ関わる人々が幸せになれるか?」を追求するのは,研究テーマをデータベースに切り替えた今でも,変わりません.
テーマ1: 仏典の情報処理 [E]
キーワード: ディジタルアーカイブ,文書読解支援,画像処理
数百年前,あるいは千年以上前に,日本では,多数の僧侶が経典を書写していました.仏教がインドで興り,東方へ伝来していくなかで,中国語に翻訳された「漢訳仏典」が中国,朝鮮,そして日本で読まれ,書かれ,流通しました.それらのいくつかは今でも寺院に保管されています.
仏教学や国語学,考古学などにおいて,そういった史料を活用できるようにするため,国際仏教学大学院大学などの研究者らが,金剛寺や七寺といった寺院を訪問し,座主の了承の下,高精細ディジタルカメラで経典を撮影して電子的に保存しています.時間経過による劣化や虫食いなどのため,経典の文字がすべて読めるわけではありません.また,横長の巻物を撮影しているので,撮影画像を読むときには,コマごとの重複部分に注意しないといけません.
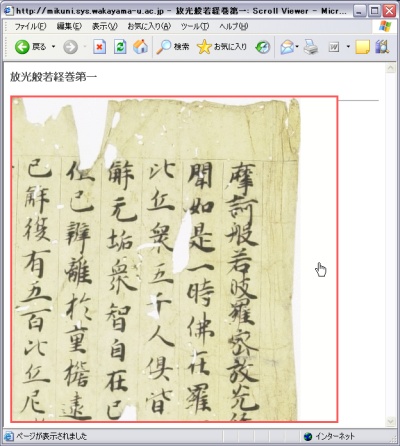
このような問題がある中,私たちは,撮影画像の余分な箇所を取り除き,一つの経典として結合するのを自動化するソフトウェアを開発しています.結合画像は,画像のサイズもファイルサイズも大きくなってしまいます(一例を挙げると,横が約30000ピクセル,縦が約1000ピクセル,40MBという画像を作成しました)が,これを適切に細分化してサーバに蓄積しておき,ブラウザでスムーズに経典画像を見ることができるようにしたアプリケーション,「Scroll Viewer」も開発しました.
以下の図が,初期バージョンのScroll Viewerのスクリーンショットです.静止画で申し訳ありませんが,実際のアプリケーションでは,経典の部分をマウスでドラッグ&ドロップすると,その方向に合わせて見える範囲が変わります.言ってみれば,Googleマップの経典版です.2006年度の卒業研究では改良が行われ,画像と,対応するテキストを対照して表示する機能が追加されました(テキストも,ドラッグ&ドロップに追随してスムーズに動きます).
テーマ2: 聖教と人間関係のデータベース [E]
キーワード: ディジタルアーカイブ,経典データベース,人物情報データベース,全文検索
8〜13世紀の日本は,仏教が花盛りのころでした.真言宗,天台宗,浄土宗といった宗派ができ,貴族が年をとると僧侶になる(「仏門に入る」という言葉を,耳にしたことはありませんか?)こともしばしばでした.多数の寺院が設立され,経典(以下では「聖教」と書きます.読みは「しょうぎょう」です)が手書きされるとともに寺院で保存されました.
当時,印刷技術がなかったので,経典は手書きでした.ここで,その末尾に記される「奥書」が,経典の出自を表す重要な情報として,現代の仏教学や歴史学において脚光を浴びています.奥書には,誰が指示してどこで誰がいつ書写したか,そしてどこに奉納されたかなどが明記されています.このようなデータは,人文研究者が当時の人間関係や教学的環境を解明しようとするのを支援するものとなります.
ここまで聖教すなわち経典を中心に説明してきましたが,僧侶の人間関係に関する史料もあります.「系図書」です.活字化されているものもあります.
さて,このような聖教や人物情報をデータベースにして,検索できるようにしようとしたとき,問題がありました.こういった聖教をこつこつ集めて電子化している研究者より,データをいただいたのですが,あるデータ群はMicrosoft Access,別のデータ群はExcel,となってます.ファイルフォーマットだけでなく,表の構成(どの列はどんな情報か)も,まちまちです.
このような不便をなくすため,私たちは,データを統合して,使いやすいUI(ユーザインタフェース)で検索できるようなシステムを構築しています.具体的には,人物名を入力すれば,どの系図書のどこに出現するかを表示するシステムや,全文検索エンジンを使って,構造化された多数の文書から適切な聖教情報を瞬時に求めるシステムを開発してきました.
現在は,人間関係情報と聖教情報を連携させたデータベースの設計・構築を試みています.
テーマ3: 医療・介護の支援システム [E]
キーワード:遠隔看護支援,健康管理
介護保険制度が2000年に始まったものの,介護者も医療従事者も,負担が減っているようには思えません.私たちは,介護における負担を取り除き,要介護者と合わせて皆が快適に生活できるようになるのを,情報通信技術を生かして支援できないかと,考えています.
私たちはまず,高齢者向け介護支援システムを作り,そのノウハウをもとに,小児患者とその家族向けの介護支援システムを開発してきました.それらのシステムでは,要介護者(小児患者について介護者)が能動的かつ定期的に,要介護者の健康状態をサーバに送り,医療従事者がそれを見て今後の治療や介護サービスの参考にしてもらうものとなっています.
この研究は,和歌山医科大学,和歌山県看護協会,和歌山看護専門学校との共同研究プロジェクトとして実施しています.その中で私は,データベースシステムの開発や,評価実験におけるデータ管理といった活動をしています.
利用者ごとにシステムを開発しているだけでなく,データベースでどのように健康情報を管理すればよいか,という問題意識のもと,「単語帳モデル」に基づくデータ管理方式を考案しています.
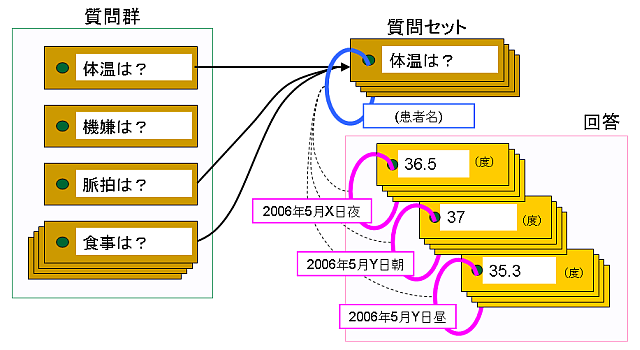
テーマ4: アンケートに対するデータマイニング [E]
キーワード: アンケート作成分析支援,統計処理,判別分析
世の中では,紙上,ネット上問わずいろいろなアンケートが行われています.また,インターネット上で質問文を編集したり配置したり,回答を受け付けて様々な角度から分析できるものもあります.
私たちは,脳卒中と,労働生活の質(Quality of Working Life)を対象として,データマイニング手法を用いた分析手法を考案し,適用しました.脳卒中アンケートでは和歌山県内の約700件の回答に対して分析を試み,危険因子については,脳外科学の知見に沿った傾向を確認できました.
テーマ5: 全文検索システム
キーワード: 全文検索,ディジタルアーカイブ
近年,ウェブ上で扱われる情報の量は加速度的に増加していく傾向にあり,またそのようなデータから自分の欲しい情報を検索したいというニーズも強まってきました.皆さんも,レポートなどの調査を行う際,GoogleやYahoo!などで検索をしたことがあるのではないでしょうか?もしかすると,次のような疑問を抱く方もいるかもしれません.「その膨大のデータの中からどのように欲しい情報を取得しているのだろうか?」 その際によく用いられているのが,全文検索という技術です.
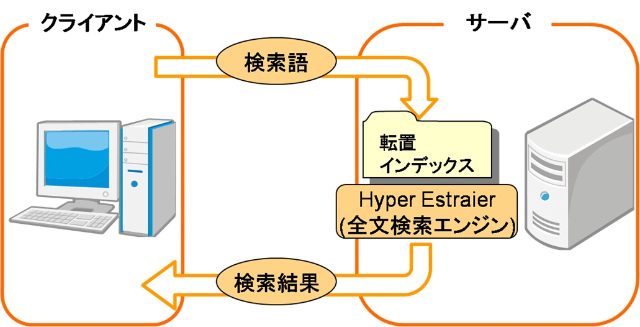
全文検索とは「複数文書にまたがって,文書に含まれる全文を対象とした検索」(Wikipediaより)のことです.これには大きく2種類の方式があります.まず一つは,逐次検索です.LinuxなどUnix系列で利用可能な,grepと呼ばれるコマンドがこれに該当します.データベースで,LIKE演算子による部分一致検索も,逐次検索と言えます.この方式は,特に準備もなく正しい検索結果を得ることができるため,手軽に利用することができます.その分,データが膨大になると結果が出るまでに,非常に時間がかかってしまいます.もう一つが,インデックスを利用する検索方式です.これは逐次検索とは違い,前もってインデックス(索引とも言います.書籍の後ろに,見出しと出現ページ数がついているページも「索引」と呼ばれますが,そのコンピュータ版と考えてください)と呼ばれる情報を作成しておく必要はあるものの,結果を瞬時に得ることができるという強みがあります.しかし,インデックスの作り方によっては,検索漏れが生じる可能性があります.なお,全文検索エンジン(インデックスを作成するタイプの全文検索ソフトウェア)には,Namazu,Lucene,Hyper Estraierなどを挙げることができます.
当研究室では,インデックスを利用した全文検索エンジンをもとに,人文学の研究者のための全文検索システムを構築しています.これまでに作成してきたシステムには,途中の1文字が不明でも検索可能な漢訳仏典全文検索システム,デスクトップPCだけでなくネットブックからでも,聖教の書誌情報(典籍名,所蔵,書写年など)の検索を可能にした聖教書誌情報全文検索システムなどがあります.
検索のイメージは図のようになります.なお,「どの文書には,どんな情報(一般に複数)が含まれているか」というデータの持ち方では,高速な検索はできませんが,これを「どんな情報は,どの文書(一般に複数)に含まれているか」に変換してデータを持たせておけば,高速な検索ができるようになります.そのようなデータを「転置インデックス」と言います.
テーマ6: ソフトウェア理解支援 [E]
キーワード: ソフトウェア工学,発想支援法,SQL
書いたプログラムが「正しく動く」ことを確認するのに,「動かしてみる」というのは基本中の基本です.文法エラーがあれば,実行する前にエラーメッセージが出て終了してくれます.処理時間を知りたければ,入力やデータセットを用意すればいいのです.
しかしそれでは,書いたプログラムが「適切である」ことまでは確認できません.例えば,プログラムの一部を取り除いても,動作が変わらないなら,取り除きたいものです.しかし,何らかの理由で取り除けないことを,計算機が知ることは一般にできず,人間の判断を必要とします.プログラムコードを人間が見てその内容を判断したり,プログラムの改善につなげたりすることをコードインスペクションといい,ソフトウェアの品質向上に役立つ技術です.
我々は,SQLを対象として,clamshell diagramという図解表示でコードインスペクションを支援する試みを行っています.
SQLは,データベースへの問い合わせのためのプログラミング言語です.宣言型であり(CやJavaなどは「手続き型」と呼ばれます),処理効率については「簡潔で複数の文」よりも「複雑でも単一の文」のほうが好ましく,PHPなどの言語で書かれたプログラムの中に文字列として埋め込まれて記述される(テキストエディタで見ると,SQL文が1個の文字列で表され,その中の何がSQLのキーワードでどれはテーブル名・カラム名なのかが一見して分からない)ことが多いといった特徴から,コードインスペクション支援の必要性を感じました.
clamshell diagramというのは,2つの対称な木構造の組み合わせで,情報の結びつきを表現しようという図式です.「思考展開図」と呼ばれる,発想支援の図式が元になっています.以下が作図例です(クリックすると拡大します).
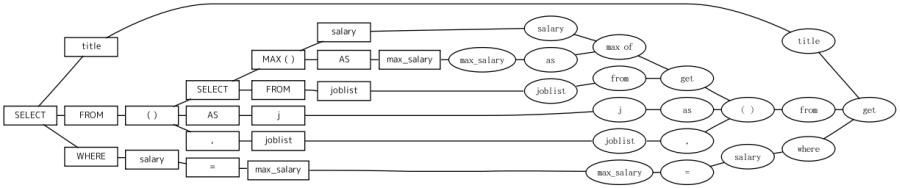
左半分の木を,根から前置順(preorder)で探索すると(若干特殊な読み方もしています),SELECT title FROM ( SELECT MAX ( salary ) AS max_salary FROM joblist ) AS j , joblist WHERE salary = max_salaryというSQL文が復元できます.右半分の木も同様にして(こちらも特殊な読み方が入っています),get title from " max of salary as max_salary from joblist " as j and joblist where salary = max_salaryとなります.これは,職業名(title)と給与額(salary)の2つの属性からなるテーブル職業リスト(joblist)の中で,給与額が最大の職業名(複数あればすべて)を求めるというSQL文です.
clamshell diagramを使うと,断片化されたそれぞれの情報が,全体としてどの位置づけにあるのかを知ることができます.また,対称関係から,課題と解法に関してどのように情報が表現され関連づけられているかが分かるようになっています.
これまで,SQL文に対してclamshell diagramに変換するソフトウェアを作りました.全体の処理はRubyで記述し,構文解析にはそのライブラリであるRaccを,また描画にはGraphvizを用いています.読みやすさを向上させるのが今後の課題です.
テーマ7: 訓点資料の読解支援
キーワード: デジタルアーカイブ,訓点資料,翻刻,文字領域,Webアプリケーション
現在,古写経を中心とした文書の電子化,およびデジタルアーカイブシステムの構築が進められています.そういった試みから,日本の言語や文化を知るために活動が支援されつつありますが,漢文に送り仮名やヲコト点が付与された訓点資料においては,文書の翻刻(古文書や写本等を読める形式にすること)やそれを扱うシステムの提供が十分になされておらず,解読支援環境の整備が求められています.
そこで私たちは,訓点資料における解読支援環境の確立を目指し,訓点資料を対象とした翻刻支援システムの構築を行ってきました.システム構築にあたり,訓点資料が手書き文書であることや,訓点資料に含まれる多様な記述情報に対応する必要がありました.そこで,本システムでは訓点資料の記述情報を文字領域や点座標としてデータベースに登録できるようにし,情報間の関連付けを行うことで解決を図りました.
また,座標情報を用いた記述情報の自動取得機能を導入して,入力の手間を省く試みを行いました.座標入力の方法として,HTML5 Canvasを用いた画像ベースのインターフェイスを実装することで,マウスを用いて資料画像上に入力する仕組みを実現することができました.

テーマ8: 系図データ処理
キーワード: 系図,データベースシステム,情報の抽出,画像処理,デジタルアーカイブ
系図とは,血縁関係や継承関係,財産,地位,学芸などを図式の形で表現したものです.系図上では一般に人物名同士を線で結んで親子関係や兄弟関係を表現しており,また人物名の周辺に,付随情報が記されることがあります.近年では,紙に書かれた系図について,画像化やテキスト化,およびデータベースによる管理がなされています.
当研究室では系図画像データや位置情報付きテキストとして表現された系図データを対象として,系図画像上の線分検出による人物名と付随情報の識別,人物同士ならびに人物と付随情報の関連付けの自動化を試み,元の系図画像を利用して系図の検索や閲覧が可能なデータベースシステムの開発を行っています.


テーマ9: 災害記事データベース
キーワード: 記事データベース,災害情報,ブログ,自然言語処理,全文検索
近年,東北大震災や熊本地震を初めとして,地震や台風などの災害が多発しており,防災への意識が高まってきています.その備えとして,防災に関する知識を得ることが重要です.そこで当研究では,災害記事データベースの構築を行い,災害に関する記事を収集しながら,全文検索のためのインターフェイスを公開しています.
具体的には,Yahoo!ブログやAmebaブログ,産経新聞等の災害関連の記事を自動的に格納し,それらに対しLDA (Latent Dirichlet Allocation)を用いて,トピックの抽出とスコアリングを試みています.

テーマ10: 情報リテラシーの理解度テスト
キーワード: 情報リテラシー,理解度テスト,CBT (Computer Based Training/Testing)
和歌山大学システム工学部の1年生向け情報処理教育には情報処理Ⅰ・情報処理Ⅱの2科目があり,このうち情報処理Ⅰは情報処理リテラシーを学習する科目で,学内計算機環境やインターネットリソースなどを適切に使用するための知識や,アプリケーションの使い方,情報システムの仕組みについて学ぶ授業です.授業の支援として学んだ内容の見直しと振り返りができる問題セットの開発および学習支援環境の提供を行っています.

問題を理解度テストのような形で提供する場合,よいテストの整備・提供が求められます.よいテストとは次の2つの要素を満たすことです.1つは信頼性であり,「テストのスコアは,常に受験者の能力の大小を言い当てている」と表され,もう1つは妥当性と呼ばれ,「テストで問われる内容と,実際に測定されるべき能力とがマッチしている」に対応付けられます.信頼性および妥当性を満足するような理解度テストを作るときにかかる手間を,問題の自動生成と項目反応理論による能力値測定により軽減することを試みました.
問題の自動抽出にあたり,授業資料(PowerPointファイル)からテキストを取り出した上で,形態素解析により用語となる語句を獲得し,用語リストを作成しました.その後,WordNetという概念辞書を用いて用語の定義や上位語を取得し,問題テンプレートと組み合わせることで問題文を作成します.誤選択肢は,WordNetにおいて関連語を検索し,取り入れることとしました.
項目反応理論による能力値推定は「問題が易しかったから正解が多かったのか,受験者の能力が高いから正解が多いのか」といった課題を解決した項目反応理論によってテスト項目の難易度やテストがどれだけ学習者の能力を判別できるものであるかを確率論的に推定し,問題の妥当性を検証することを目的として採用しました.20問からなる問題セットに解答してもらった結果から,それぞれの項目反応曲線を作成し,問題の良し悪しを判断する手がかりとなりました.


テーマ∞: その他のデータベースシステム [E]
キーワード: Webアプリケーション,データベースシステム,人間中心設計
これまで,教務支援,電子商取引,3次元製品デザインといった,各種業務のためのデータベースシステムを手がけてきました.教務支援とは本学内のWISSのことで,休講・補講・試験・呼び出しなどの情報を蓄積し,該当する学生にのみメールで送信しています(Webからのアクセスもできます).
それぞれのシステムは,研究室内で教員・学生の討論だけでなく,システム利用者(計算機利用に必ずしも詳しくない)の意見を得ながら,設計,構築をしていきました.