背景と目的
店舗経営における重要な問題として,在庫管理が挙げられます. 商品が売れ残ると管理維持のコストや廃棄が増加し,逆に在庫不足になると販売機会の喪失や顧客の減少が生じてしまいます. これより,売れる数だけ商品を仕入れる必要がありますが,全ての商品がいくつ売れるのか人手で予測するのは非常に困難です. 在庫の数を基準に発注を行うのではなく,需要予測が必要となります.
需要予測に関して,様々な企業によって需要予測システムの開発が行われていますが,全ての商品を高精度で予測出来ているわけではありません. 上記で述べた様々なコストロスを防ぐためにも,予測ができない商品を予め発見する必要があります. そこで本研究では,「POSデータ5分類手法」について開発と検証を行っています. POSデータを分類することによって,需要予測の「当たる」「当たらない」を事前に明確化します. この研究により「需要予測前に予測の可否を判断する」効果や「全自動で需要予測及び発注をする」効果が期待されます.
※POSデータとは: Point Of Salesの略で,小売店などの店舗のレジで商品が売れたときのデータのことを指します. 商品が売れた時間,店舗,数,値段,客数,気象情報,などの情報を収集することが可能となります.
POSデータ5分類手法
本研究で開発・検証中である「POSデータ5分類手法」の概要について記します.
(1) 分類器構成
図 1に,分類器の構成を示します.分類器にPOSデータが取り込まれると,学習データと検証データに分割されます.その次に,学習データからランダムフォレストの需要予測モデルを作成します.そして,作成された需要予測モデルに対し検証データで検証を行います.これにより,図 1に示す「R2」と「MAE」の評価指標が算出され,この2値によってPOSデータを5つに分類します.最後に,「POSデータ5分類手法」は,分類先の各々のデータ特徴に応じて予測(発注)モデルを提案します.
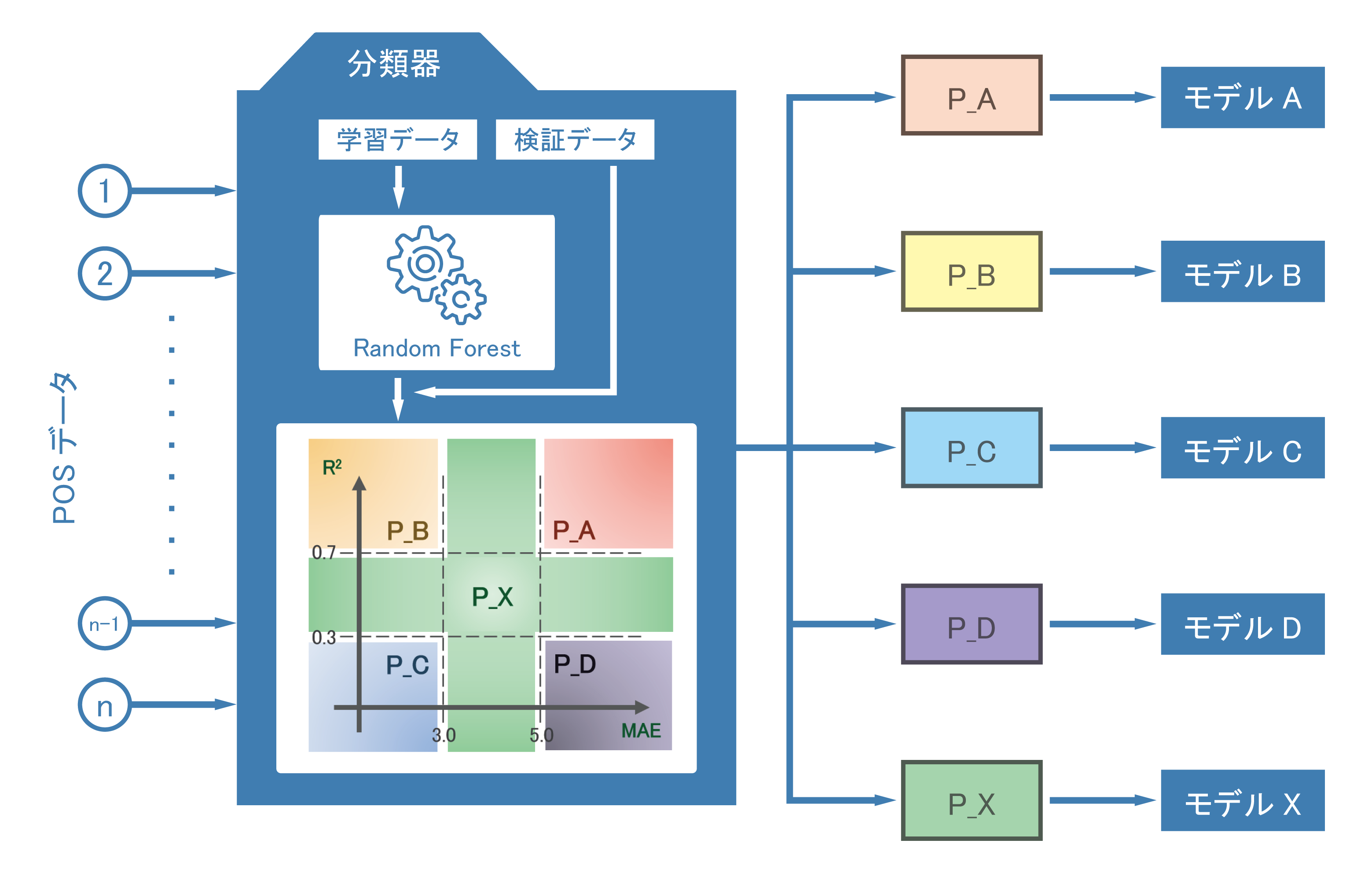 |
図 1. 分類器構成図 |
|---|
(2) 各分類の特徴
図 2に,P_Xを除いた各分類の主な需要曲線を示します. これは,とある小売店のPOSデータを用いて需要予測を行ったときのグラフになります. 図 2中のグラフについて,縦軸は商品の需要数(販売量)を表し,横軸は時間(一日単位)を表しています. また,青線は実際の需要数で,黄破線は予測した需要数です. 図 2や,分析により以下のことが分かっています.
- P_Aでは,青線と黄破線がほとんど重なっており,高精度に予測が的中していることが確認できます. ゆえに,需要予測を機械学習モデルで行って大丈夫な商品群となります.
- P_Bでは,青線と黄破線に少し誤差が見受けられます. これは,誤差の評価指標であるMAEが低精度となっていることが起因しています. 分析を行ったところ,P_Bは,そもそも一日に販売される量が多い(平均値と中央値の差が大きい)商品が数多く存在することが確認できました. そのため,全体的な需要のピークの山は予測出来ていても,その正確な数までは当てることができていません.
- P_Cでは,P_Bと相反して,モデルの当てはまり度を示す評価指標R2が低精度となっています. そのため,需要の増減やピークを上手く追うことができていません.
- P_Dでは,機械学習モデルによる需要予測が的中していません. ゆえに,この商品群は需要予測ではなく,店の在庫が減り次第発注を行う方式(セルワンバイワン)による在庫管理を行う必要があります.
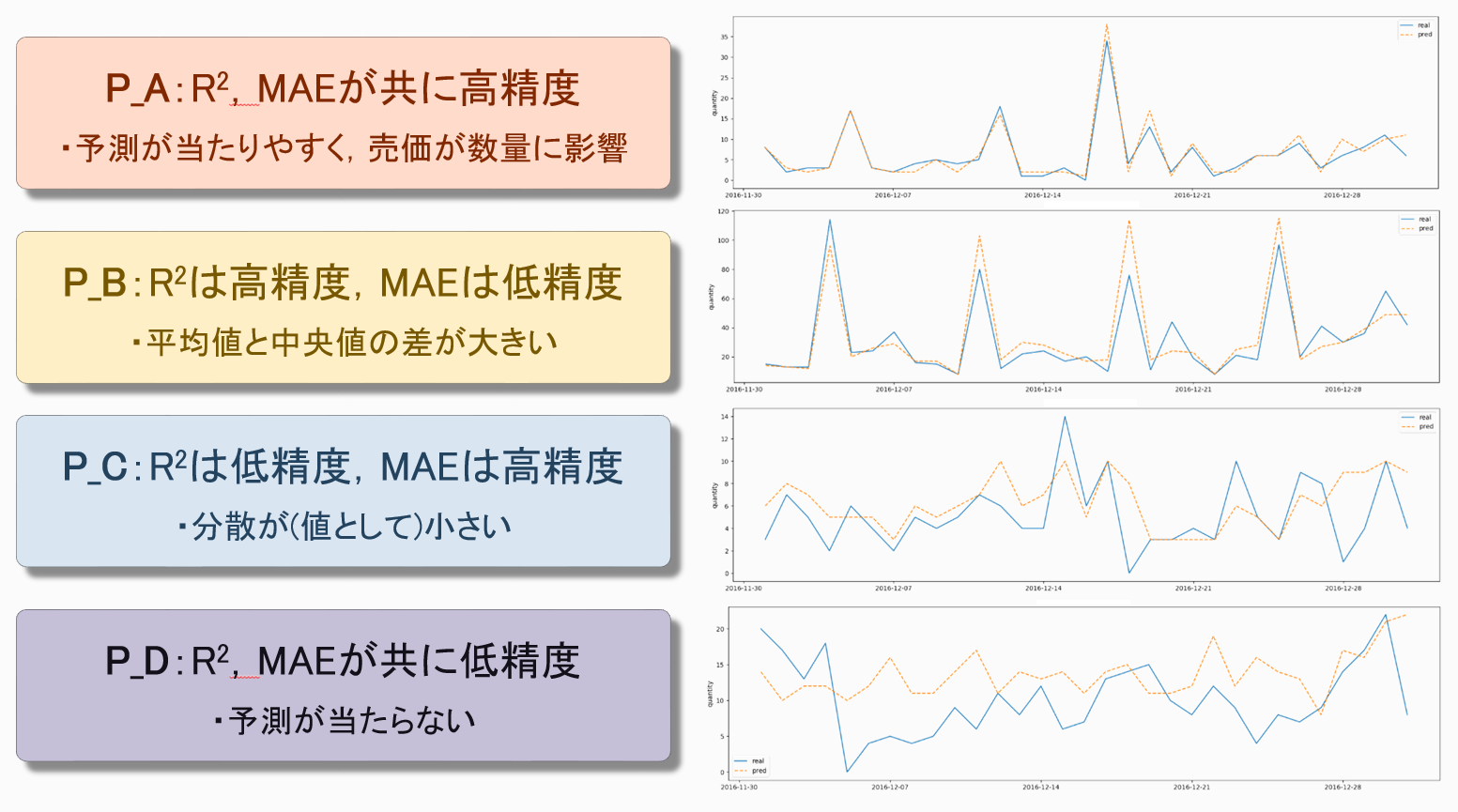 |
図 2. 各分類の需要予測結果(P_Xを除く) |
|---|
今後はパターンX(P_X)の特徴分析や,データの量・質に対する「POSデータ5分類手法」の妥当性を検証していきます.
対外発表
- 安田大誠,吉野孝,松山浩士: POSデータを用いた需要予測手法の事前自動判別に関する基礎検討, 情報処理学会関西支部 支部大会 講演論文集,B-03,pp.1–3 (2019-09-23).
連絡先
※[at]は@に置き換えて下さい.
- 安田 大誠 : s206269[at]wakayama-u.ac.jp
- 吉野 孝 : yoshino[at]wakayama-u.ac.jp