1背景と目的
結婚披露宴の席次表の作成は依然として手作業に依存しており,招待客数の増加に伴って招待者同士の関係性や配席マナーへの配慮が複雑化し,作業負担が大きくなるという課題があります.
そこで本研究では,過去の席次データを機械学習モデルに学習させ,配席を自動で行うことで,結婚式準備における新郎新婦の負担を軽減することを目的とし進めています.
2使用したデータセット
使用したデータセットは,実際の披露宴で利用された,1つの会場における配席済みデータ100件です.
表1にデータセットの中身の一部を示します.
| 表1.データセットの一部 | ||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
3提案手法
本システムは,2段階で構成されています.1段階目は,ランダムフォレスト(RF)による学習,2段階目は,遺伝的アルゴリズム(GA)による探索です.
(1) RFによる学習
「席次表の特徴量」と,作成した評価関数で算出した「席次表のスコア」をもとに学習を行い,「席次表の特徴量」から「席次表のスコア」を予測するモデルを作成します.
「席次表の特徴量」は以下の通りです.
- 使用したテーブル数
- 各テーブルごとの平均の人数
- 新婦側の招待者の平均位置
- 家族・親族の下座配置率
- 各テーブルの最も多いグループの招待者の割合の平均
評価関数は以下の観点で構成されており,配席を行う上で守るべきルールを基に作成しています.
- グループのメンバー同士の距離
- 新郎側・新婦側のエリア配置の一致率
- 新郎新婦の家族グループの下座配置率
- 各テーブルの定員に対する着席人数の割合の平均
(2) GAによる探索
遺伝的アルゴリズムを用いて,スコアの高い席次表を効率的に探索します.
図1に遺伝的アルゴリズムの工程を示します.
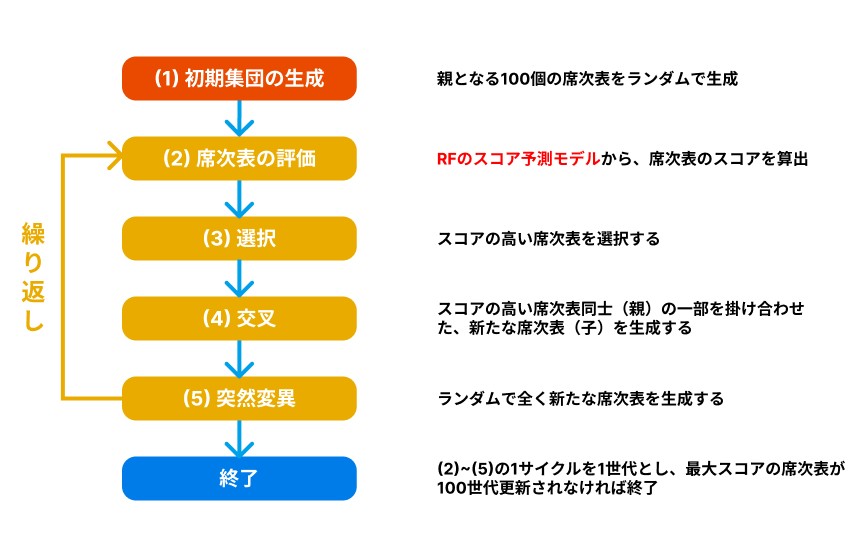 |
| 図1.遺伝的アルゴリズムの工程 |
|---|
4実験と結果
サンプルデータ100件のうち,特徴量のユークリッド距離が平均から遠い20件を非標準データとして除外し,残りの80件のうち79件を学習データ,1件をテストデータとして使用しました. テストデータは,サンプルデータから配席位置を除いた招待者情報です.テストデータをもとにGAによって生成した席次表のうち,評価項目の条件を満たすものを集計しました. 評価項目の条件は以下の通りです.
- 条件1:家族が下座に配席されている
- 条件2:招待者が新郎新婦側のエリアを守って配席されている
- 条件3:グループごとにまとまって配席されている
| 表2.条件を満たした席次表の数 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
結果として,生成した席次表の9割以上で家族が下座に配席されていることが確認されました. これは実際に使用された席次表と同等以上に,家族の下座配置を遵守していることを示しています.
また,新郎新婦側のエリア配席とグループのまとまりの条件を満たす席次表の割合は5割程度で,実際に使用された席次表よりも低い結果となりました. 新郎側・新婦側の招待者数に大きな差がある場合や,少人数のグループが多い場合に,条件を満たしにくいことがわかりました.
図2に実際に使用された席次表と本手法で生成した席次表の1つを示します.
 |
| 図2.実際に使用された席次表(上)と本手法で生成した席次表(下) |
|---|
5おわりに
本研究では,機械学習を用いて結婚披露宴の自動配席手法を提案し,実験によって家族の下座配置の条件を高い割合で満たせることを確認しました.
今後は,新郎新婦側のエリア配席とグループのまとまりの条件を満たす席次表の割合を高めるために,評価関数の改良や探索アルゴリズムの工夫などを検討していくとともに, 会場ごとに異なる配席傾向に対応できるようにすることも目指していきます.
発表
- 志村駿介,吉野孝(和歌山大),松浦孝博,髙妻辰弥,里岡洸輔(PIEM): 機械学習を用いた結婚披露宴の自動配席手法の提案,情報処理学会第88回全国大会,7N-02(2026-3).
連絡先
- 志村 駿介:s2310116 at sys.wakayama-u.ac.jp
- 吉野 孝:yoshino at sys.wakayama-u.ac.jp