1背景と目的
近年,デジタルアーカイブは有形無形の資源をデジタル化することで,多種多様な資源を収集・蓄積・保存・提供することができるサービスとして利用されています. 利点として分散されたデータを集約できることや教育や観光への二次利用が可能であることが挙げられます. しかしデータの追加・更新の停滞や操作性の向上が見られないなどの問題点があります. このことからデジタルアーカイブに対して,ユーザの評価や支援が必要であると考えました.
また東日本大震災後,様々な組織が景観を保存することを目的としたデジタルアーカイブプロジェクトを実施し,震災前の写真や動画の大規模収集を行っています. このことから,我々は景観を保存することが観光支援につながるのではないかと考えました.
そこで本研究では,web上からデジタル写真の自動収集を行い,そのデータを観光利用できる形に再編成するシステムを開発しました.
2システムの概要
本システムは,web上からデジタル写真を自動収集し,観光利用しやすい形にデータを再編成します.
図1のようにデジタル写真と付加する情報を取得するwebサーバとデータを蓄積・再編成するデジタルアーカイブから構成されます.
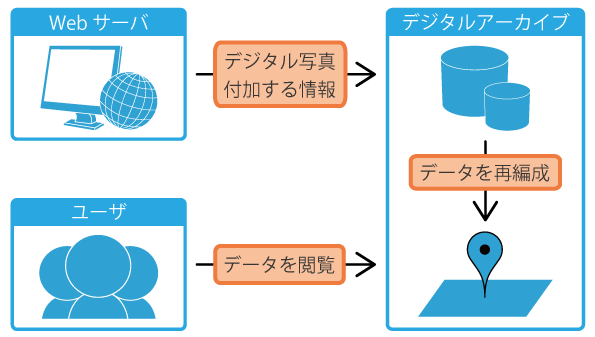 |
| 図1. システム構成 |
|---|
3システムの機能
(1) デジタル写真の自動収集
Google画像検索を利用して,デジタル写真の収集を行います. 画像検索によりデジタル写真の情報として,タイトル・画像ファイルのパス,画像が存在するページのリンク, 画像が存在するページのtopへ繋がるリンク,スニペット,MIMETypeを取得することができます.
また情報抽出を行い,アップロード日時・撮影場所・色・印象を取得します.
(2) データの再編成
デジタル写真をGoogleEarth上にマッピングし,データを保存します.
デジタル写真をアイコンとして表示し,情報抽出により,得られた場所にマッピングします. アイコンをクリックすることで,デジタル写真に関する情報を閲覧することができます.
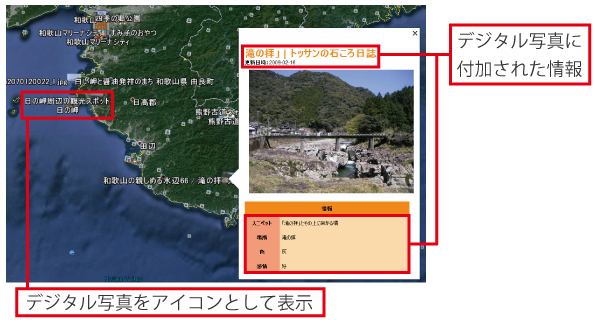 |
| 図2. Google Earth上にデジタル写真をマッピングしたデータ |
|---|
4情報抽出
(1) アップロード日時
デジタル写真がweb上にアップロードされた日時を記録します.
情報抽出を正確に行うために,抽出手法を提案しました.優先順位は(A),(B),(C)の順に適用します.
(A)RSSフィードから記事の記載日時を取得
(B)画像が存在するページの最終更新日時を取得
(C)画像が存在するページのテキストに記述された日時を取得
(2) 撮影場所
デジタル写真が撮影された場所を記録します.
情報抽出を正確に行うために,抽出手法を提案しました.優先順位は(A),(B)の順に適用します.
(A)画像が存在するページのテキストから場所を抽出
(B)タイトル・スニペットから場所を抽出
(3) 色
デジタル写真の色を一色で表現し,記録します.以下に抽出手順を示します.
(1)画像を構成する各ピクセルの色をRGB で取得
(2)HSV に変換
(3)赤・オレンジ・黄・緑・シアン・青・紫・ピンク・白・灰・黒に分類
(4)11 色に分類した色の中で最もピクセル数が多い色を画像の色とする
(4) 印象
デジタル写真の印象を感情表現を用いて,記録します.
画像が存在するページのテキストから抽出し,「喜, 怒, 哀, 怖, 恥, 好, 厭, 昂, 安, 驚」の10項目に分類します.
口頭発表
- 山本理絵,吉野孝:地理情報に関連づけられたデジタル写真収集システムの提案,情報処理学会第76回全国大会,1N-6,第1分冊,pp.571-572(2014-03).
連絡先
- 山本 理絵:s165059 at center.wakayama-u.ac.jp
- 吉野 孝:yoshino at sys.wakayama-u.ac.jp