情報獲得支援システムの概要図
本研究グループでは,Web空間の中の情報や構造,人間の行動を分析して有用な情報を抽出することで,情報探索行動の効率化に貢献するための研究を行っています.
特にTwitterなどのソーシャルメディア,CiNii Articlesなどの学術情報検索やarXivなどのプレプリントサービス,cookpadなどのユーザ投稿型レシピサービスに注目し,人工知能,機械学習,自然言語処理,ネットワーク分析,データマイニングなどの技術を複合的に駆使することで,情報検索システムや情報推薦システムの飛躍的な質の向上に繋がる技術を創出します.
研究対象によって,さらに大きく次の3つのサブグループに分かれています.
なお,これは基本的に対象固有の知識を密に共有すると共に,その対象の特徴を生かした新規性のある問題・手法を扱うためで,研究に必要な技術・知識は同じです.
上記以外にも,様々な分野に適用できる基礎的な研究や,実サービスを提供するような応用的な研究も行っていて,それはその他の研究にまとめてあります.
ソーシャルメディア分析サブグループでは,ブログやTwitterなどのソーシャルメディアデータを用いた研究をしています.
情報獲得支援システムの概要図
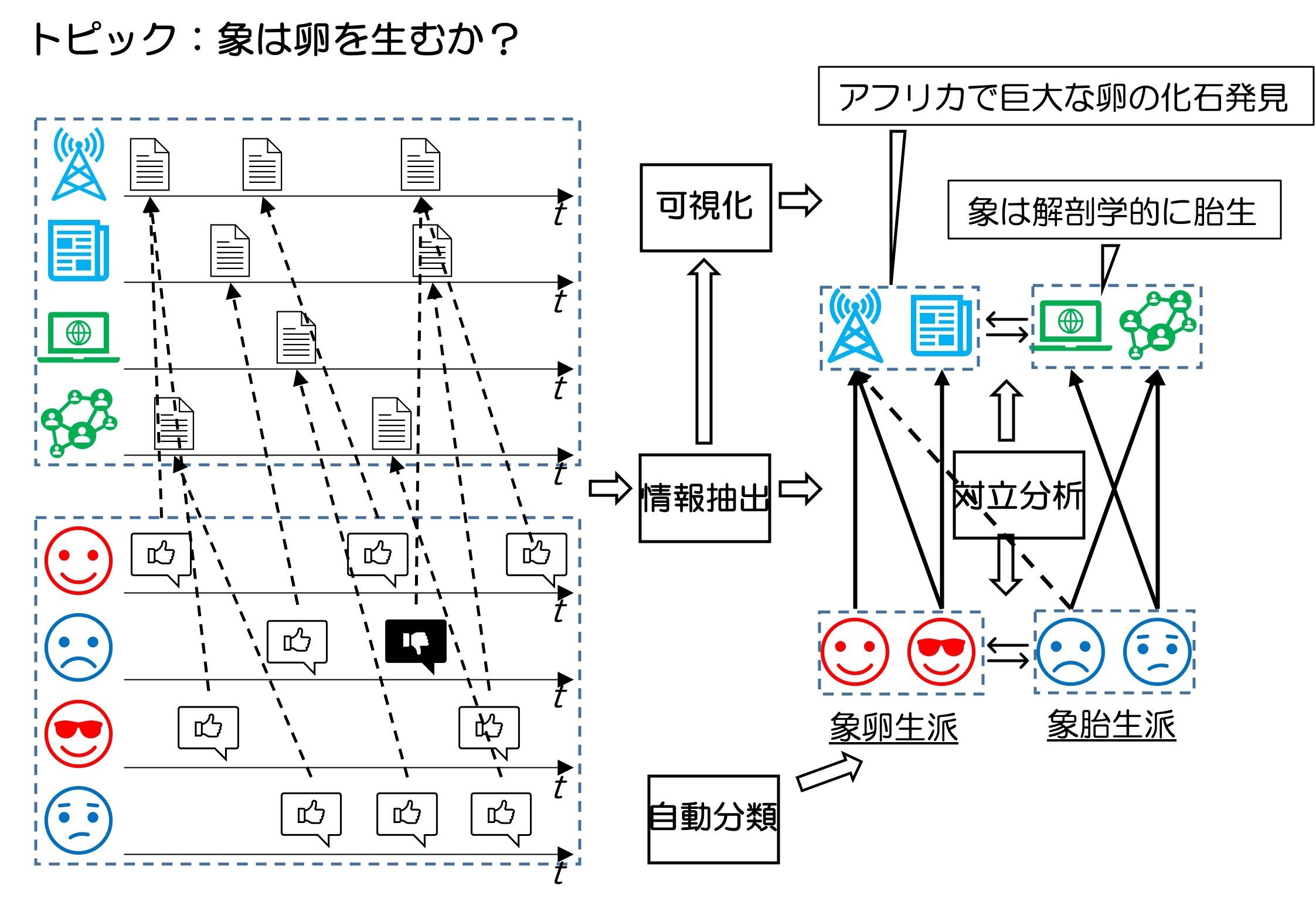
Twitterなどのソーシャルメディアの普及より情報発信者である報道機関と情報受信者であるソーシャルメディアユーザが密に相互作用できるようになり,実世界の経済活動や政権アピールなどに活用されるようになりました. しかし,フェイクニュースや釣り記事の報道や,政府の報道機関への介入や利害関係者への忖度など,情報の信頼性を損なう行為が増加するようになりました. また,協調フィルタリングなどの情報推薦やユーザの行動履歴に基づいたパーソナライズが導入された結果,情報獲得の多様性が損なわれるようになりました. このような状況で情報受信者が公平な観点から意思決定するためには,ある事象に関する異なる視点からの報道・議論の全体構造を俯瞰し,中立的な視点から多様性のある情報を理解することが必要となってきます.
本研究では,中立的な視点からニュースやツイートの理解を支援するために,論争が発生しているトピックを自動発見したり,報道機関やユーザの対立の度合いを測定したり,報道機関やユーザの論調や意見で分類することが可能なシステムを実現しようとしています.
この研究は,第17回WI2研究会学生奨励賞を受賞しています.
単語の分散表現に基づいた専門用語辞書の拡張の概要図
企業が,ソーシャルメディアのユーザの発言から自社製品の評判やユーザの嗜好・動向などの情報を正確に分析するためには専用の専門用語辞書が必要で,このような辞書の作成・検証には多大な時間とコストが掛かりました.
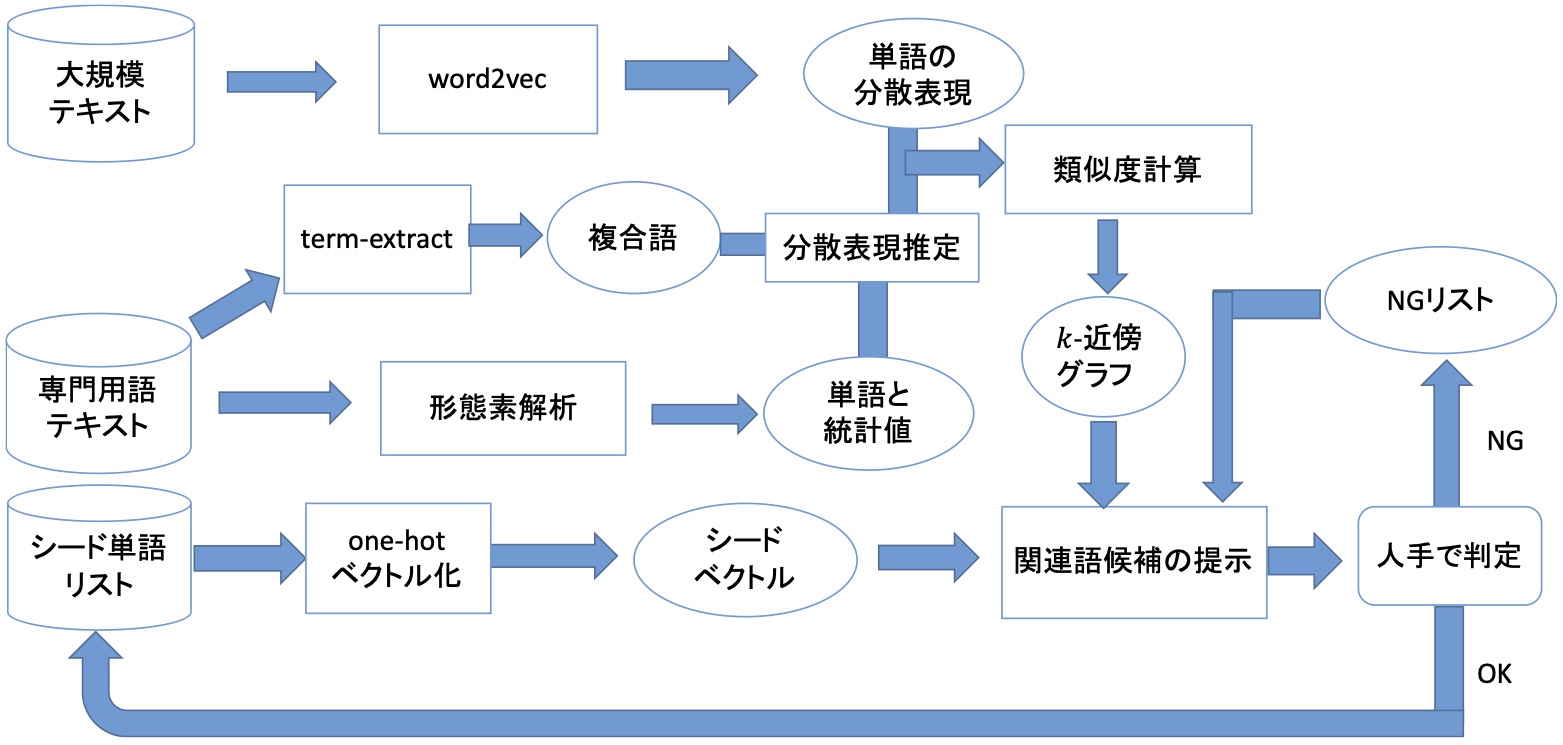
本研究では,辞書作成者が次々と提示される類似性が高い単語の真偽を判定する作業をおこなう状況を想定し,対象分野のシード単語リストから,大規模コーパスから作成した単語の分散表現と,同一分野の文書群から抽出された単語を用いて,ソーシャルメディアの特定のドメインに対する精緻な分析を可能にする専門用語辞書作成時の負荷を低減する手法を実現します.
実際には,単語の分散表現のコサイン類似度の重み付きのk-近傍グラフを作成して,シード単語リストとの関連度に基づいて関連語を推薦します. さらに,その判定結果に基づいて,シード単語リストを拡張し,k-近傍グラフ上の関連単語を効率的に探索できるように制御します. ただし,専門用語には複合語が多くword2vecの分散表現データには含まれないことが多いですが,この研究では再学習せずに単語に関する統計値(単名詞2-gramの連接頻度)を用いて比較的高い精度で未知の複合語の分散表現を推定すると共に,k-近傍グラフを修正した可変エッジ数近傍グラフを用いて,精度と網羅性が高い関連語候補の推薦を実現します.
この研究は,電子情報通信学会 言語理解とコミュニケーション研究会(NLC)2019年学生研究賞を受賞しました.
単語の分散表現を用いたLDAのトピックラベリングと時系列可視化結果の例
Bleiらが提案したLDA は,データセット内に存在している潜在的な複数のトピックを教師なし学習で推定する代表的なトピックモデルですが,トピックを単語集合として表現するだけなので,必ずしも理解しやすい結果ではありません.
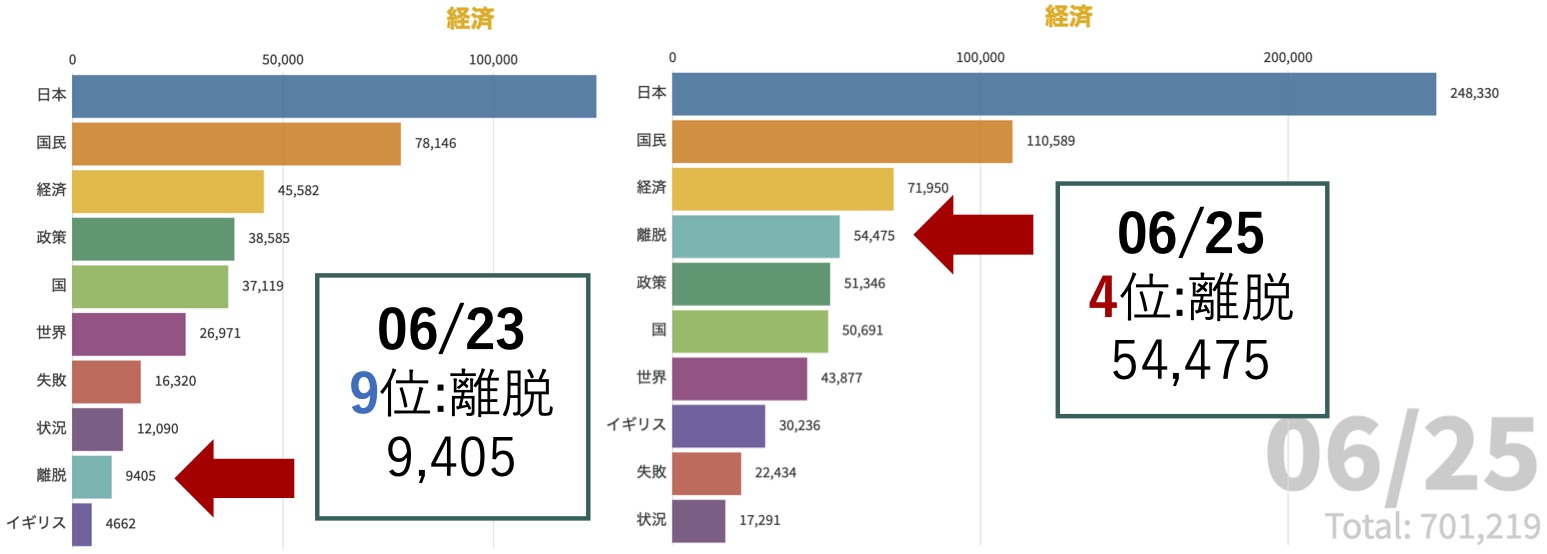
本研究では,LDAで分類されたトピックの理解を支援するために,word2vecの分散表現ベクトルを用いて,各トピックの最上位を除く単語の平均ベクトルに最も類似する単語を内容ラベル(トピックの内容を一言で表すラベル)として割り当て,さらに事前に用意した既知の論点ラベル(分析したい論点やサブトピックを表すラベル)のベクトルに最も類似する単語が上位に存在するトピックにその論点ラベルを割り当てます. さらに, 一定期間ごとにLDAを適用し,共通のラベルでトピックを関連づけて,その時系列変化をFlourishのBar chart raceを使ってアニメーションとして可視化します.
例えば,論点ラベル「経済」が付与されたトピックの時系列変化をアニメーションとして可視化すると,2016年6月23日から25日に「離脱」の順位が急に上がっていることがわかりますが,これは6月23日にイギリスでEU離脱の国民投票が実施され,24日に離脱が決定したからです.
ジオタグ付きツイートを用いた交通路の抽出の概要図
Twitterは,そのリアルタイム性の高さから,現実世界の状況を把握するソーシャルセンサとして,様々な分野で活用されています. 位置情報が付加されたジオタグ付きツイートを分析すれば,ユーザの位置を知ることができるので,今まで位置情報を定期的に取得できる専用アプリやプローブカーを使っていた人流や観光経路の分析や,東日本大震災時にGoogle Maps上と公開された「通れたマップ」のような災害時の通行可能な経路情報公開に用いることが考えられますが,実際にはツイート間隔は不定で比較的長いことから,そのままでは利用できません.
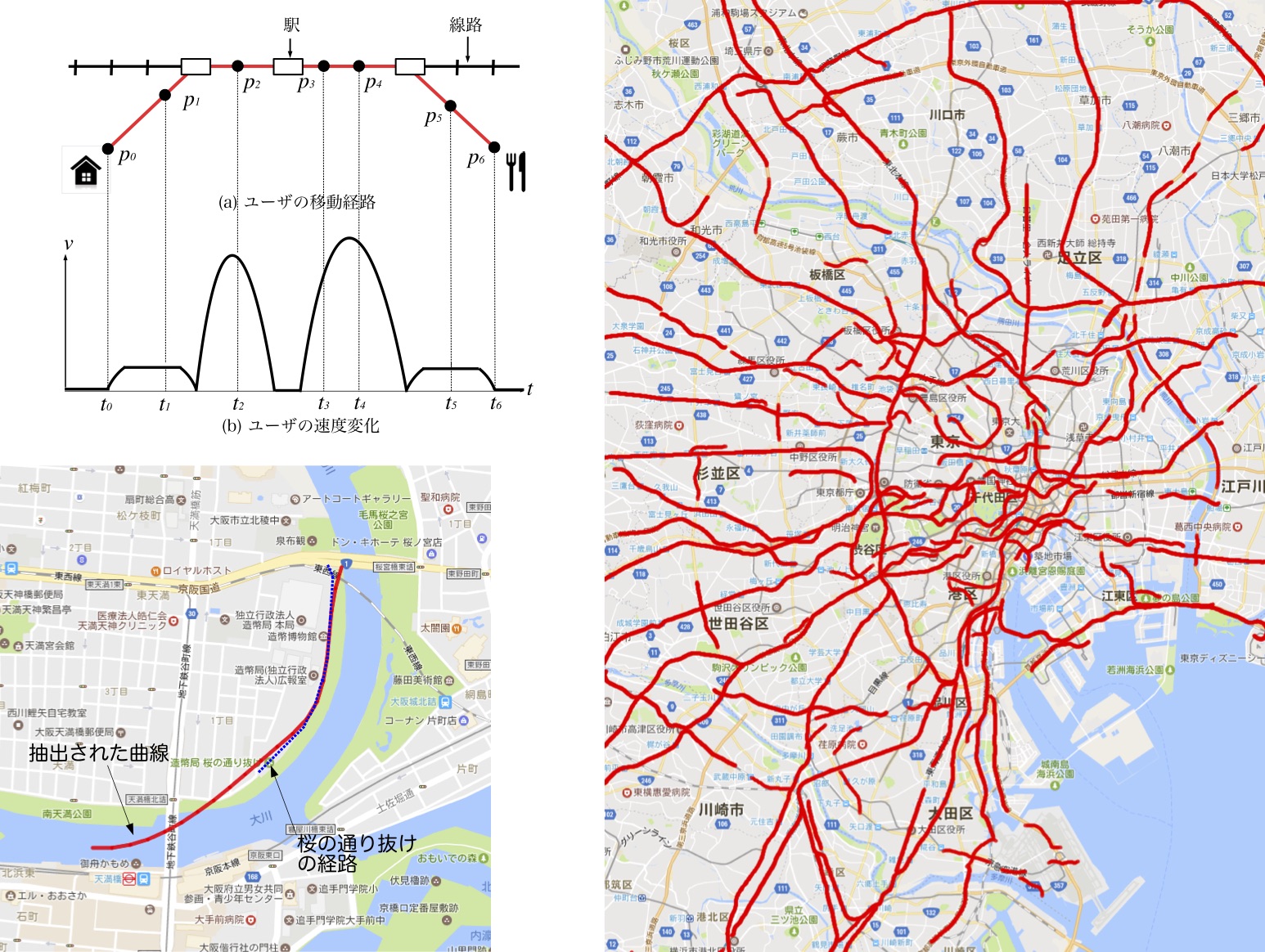
そこで,本研究では,ジオタグ付きツイートを内容や移動速度,移動距離などの条件に基づいて選別・集積して得られる位置情報から,それらの発言者たちが共通で利用している交通路を抽出する方法を提案しています.
実際には,図の左上のように,まずツイート投稿中またはその前後にユーザが移動したと推定されるツイート群を,位置と時刻を用いて抽出します. 次に,対象地域を細分化した矩形領域内のツイートを画像処理技術であるHough変換を用いて,交通路の断片である近似線分群を求めてから,連続していると推定される近似線分をグループ化して,3次スプライン曲線で近似・補間することで,連続した交通路として抽出します.
実際に,関東の東京駅を中心とするエリアに提案手法を適用すると,図の右側のようにJR山手線を中心とした鉄道路線や高速道路が比較的高い精度で抽出できることがわかります. さらに,花見シーズンの大阪造幣局周辺のエリアに適用すると,図の左下のように桜並木に移動する花見客の経路が抽出できることがわかります.
この論文は,情報処理学会論文誌:データベースに採録されました.

ブログ空間の情報伝播の可視化例
ブログやTwitterなどのソーシャルメディアの普及に伴い,そのようなサービス上に構築した人間関係ネットワーク上の情報交換が盛んになってきています. このような口コミ的な情報をうまく利用できれば,重要な情報の発見,社会動向の分析,震災時の災害情報の収集などに利用できます.
この研究では,そのような情報伝播ネットワークの構造や情報伝播メカニズムを分析して,重要な情報や議論の発見を試みます. さらに誤った情報やデマをどのように見分けるかについても研究します.
例えば,ブログや情報源の間のハイパーリンク構造からブログ空間の情報伝播ネットワークを構築して,重要な情報源を発見すると共に,各情報の性質を推定することができます.
この研究は,日本ソフトウェア科学会コンピュータソフトウェア,情報処理学会論文誌:データベース,人工知能学会論文誌,Neurocomputingに採録されました.
学術情報処理サブグループでは,論文などの学術情報に関する様々なデータ,例えば,様々な論文などの学術情報アーカイブ,CiNii Articlesなどの検索システムの利用履歴,ソーシャルメディア上の学術情報に関する言及などを用いた研究をしています.
![]()
arXiv論文がTwitterに与える影響の分析の概要図
論文の電子化と共に電子アーカイブや論文検索などのサービスも発展したが,レベルの高い論文は少数の商業出版社による寡占状態にあるために,必ずしも論文の全文を自由に閲覧できるわけではなく,その論文購読料の上昇により購読契約を打ち切らざるをえない大学も出てきています. そこで,査読前の論文や最新の研究成果の公開を目的としたarXivなどのプレプリントサーバが注目され,研究情報の交換や学会の運営に積極的に活用されはじめています. 特に,近年のDeep Learningの急速な発展は,プレプリントサービスによる無料・早期の論文公開によって支えられています.
この研究では,arXivで発表された論文が現実世界に与える影響や,プレプリントサービスを発信源とする学術情報の流通において各ユーザが果たす役割を分析しています. その結果,arXiv論文の情報を広める専門家には,国際的に活躍している専門家以外に,日本のような特定の地域との仲介をしている専門家がいることを明らかにしました. さらに,これらの結果を踏まえて,arXiv内の論文の評価指標を考案することを目指しています.
この研究は,WebDB Forum 2019企業賞(ポスター9/9発表分)・株式会社東芝賞,第16回WI2研究会 萌芽研究賞を受賞し,国際会議WI-IAT2021にRegular Paper(採択率27.6%)として採択されました.
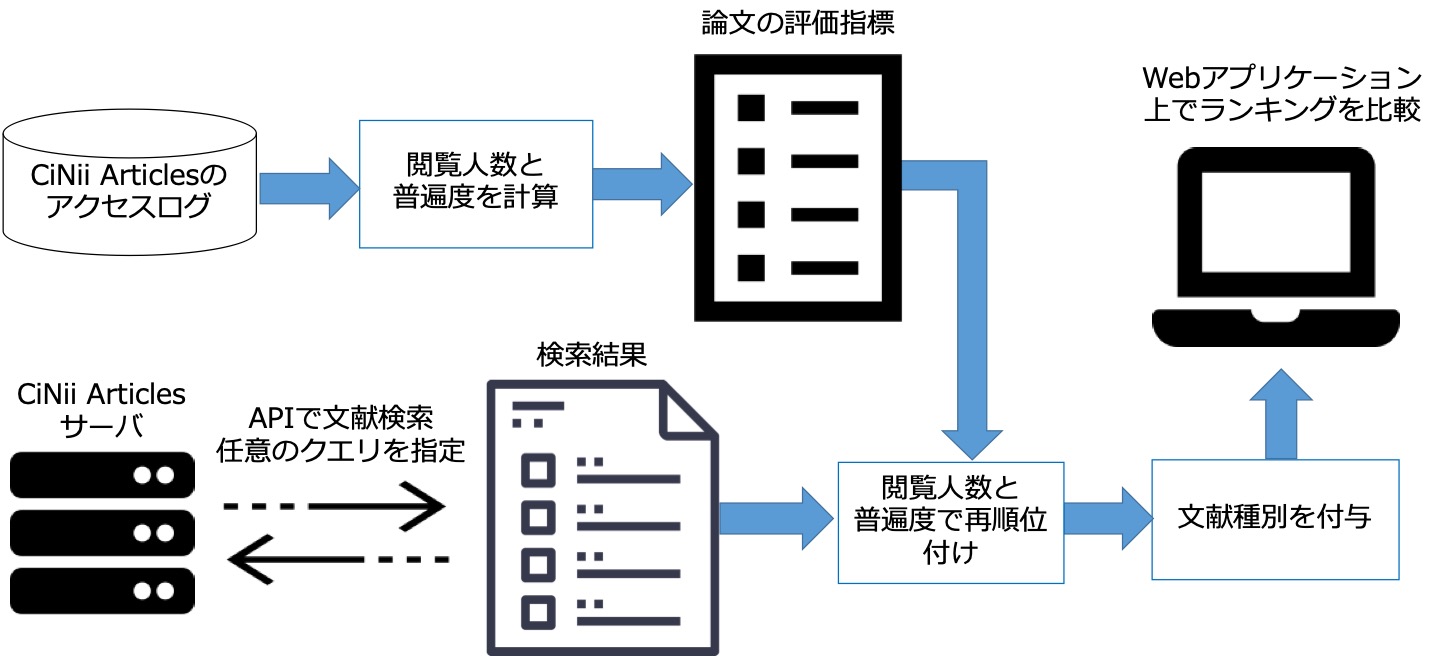
多彩な論文の評価指標を用いた学術情報検索の高度化
研究者にとっては学術文献を読むことはとても重要な仕事です. 文献や検索手段が紙媒体だった時代は,購入や図書館の貸し出しなどに手間や時間が掛かりましたが,インターネットの普及と学術出版物の電子化と共に,CiNii Articlesのような学術論文検索サービスが重要な役割を果たすようになりました. ただし,学術情報検索では,学部生,大学院生,教員,開発者などのユーザの属性によって求める学術情報の種類が違ったり,一見同じ内容であっても信頼性や価値が異なるなどの特徴がありますが,現在のシステムではこれらの特徴がほとんど考慮されていません.
本研究では,従来の論文の評価指標に加えて,検索サービスやソーシャルメディアの利用履歴から求める独自の評価指標を考案し,その特性を明らかにすると共に,それらの指標を組み込んだ独自の学術情報検索を実現することを目指しています.
現在は,オルトメトリクスなどで用いられる論文の閲覧人数やソーシャルメディア上の言及人数に加えて,その内容の普遍性を測る普遍度と,論文の検索語のバースト性(Kleinbergの列挙型バースト検出アルゴリズムを使用)を評価指標として用いています. また,その指標の違いは,学術情報の種別,検索語の内容指定語(qf-idfを使用)・分類指定語(qf-dfを使用),面白さ(佐藤らの指標を使用),検索語の可視化(word2vecで求めた単語の分散表現とt-SNEを使用)などを用いて分析しています. これらの結果を受けて,図に示すように,CiNii Articlesの検索結果を我々の提案する指標を用いて自由にリランキングできるシステムを作成して用いています.
この研究は,WebDB Forum 2019企業賞(口頭発表)・LegalForce賞を受賞し,情報知識学会誌と電子情報通信学会和文論文誌Dに採録されました.
学術情報探索システムの実行例
近年の情報交換・共有技術の進歩と共に,研究開発と技術の陳腐化の進展が早くなり,研究開発の動向の把握が重要となってきました.
この研究では,単語共起関係と共著関係を利用することで,論文の網羅的な探索を支援する方法を研究します. 例えば,共著者ネットワークのコミュニティ構造に基づいて単語を順位付けして,研究分野を指定するのに適した専門的な関連語を選択できるようにします. また,共著関係に基づいて論文をグループ化すると共に,グループの代表的な著者と,その共著者を提示することで,検索結果の概要の把握を容易にします.
食情報処理サブグループでは,NIIの情報学研究データリポジトリから公開されている,クックパッドデータセットや楽天レシピデータセットを用いて研究をしています.
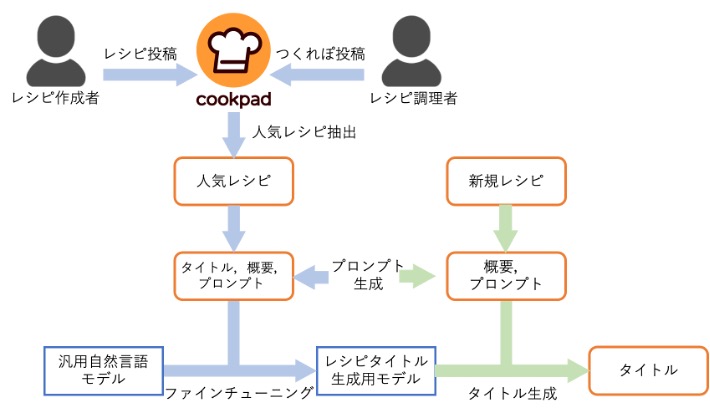
レシピタイトル生成の概要図
クックパッドのようなユーザ投稿型レシピサイトでは,例えば「ペペロンチーノ」だけで1万件を大きく越えるレシピが投稿されており,自分の投稿したレシピを検索結果からなかなか見つけてもらえません.
そこで投稿型レシピサイトの多くの類似レシピの中から,ユーザが見たくなるような魅力的なタイトルをBERTなどの大規模言語モデル(LLM)を使って自動生成します. そのために,クックパッドで多くのつくれぽが寄せられたレシピ群に付与されたタイトルは魅力的であると考えて,それらをタイトルを使ってLLMをファインチューニングします.
ただし,LLMにはハルシネーションという問題があり,レシピとは異なるタイトルを生成しがちです. そこで,この研究ではレシピの概要に加えて,レシピの概要以外の部分から自動生成したプロンプト(AIへの指示)を使うことで,「オーブンで焼くだけ!簡単ドリアの出来上がり♪人気検索1位になりました。ありがとうございます☆(2009.11.24更新)」という概要の文章から,「オーブンde簡単ドリア」(人手でつけられた元のタイトルは「簡単ドリア」)のようなタイトルを生成することができます.
この研究は,DEIM2023 学生プレゼンテーション賞を受賞しました.
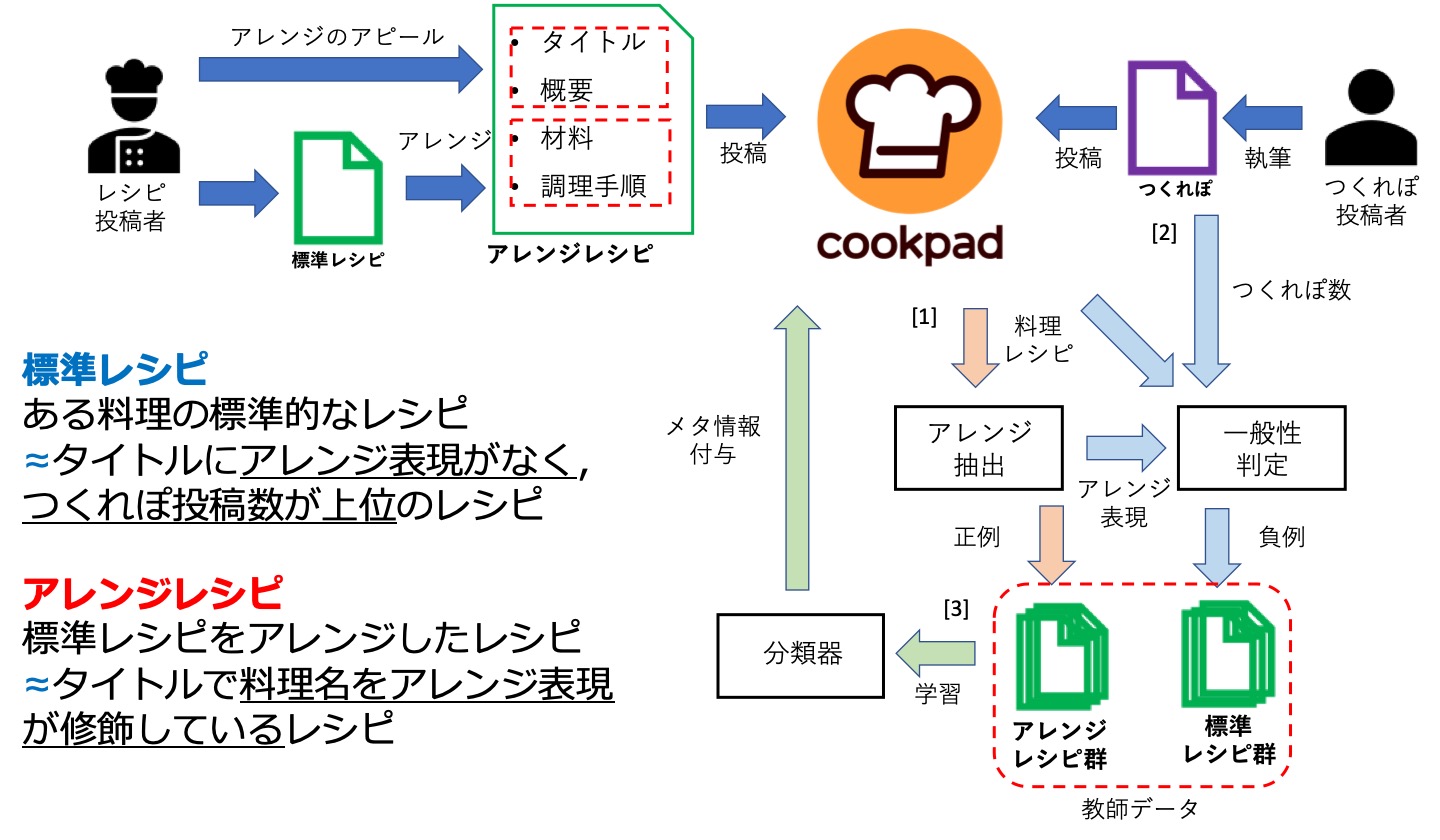
レシピへのメタデータ付与の概要図
クックパッドのようなユーザ投稿型レシピサービスの普及につれて,逆に「ユーザ投稿型レシピサービスにおける迷子問題」が深刻になってしまいました. これは,同じ料理名でも,ユーザが少し違うアレンジを施したレシピが膨大に存在して,その違いもわかりにくいので,逆に自分の好みのレシピを探し出すことが難しくなってしまうという問題です. そこで,同じ料理名の典型的なレシピが一つしか存在しないような,収録数が少ないレシピ集の方が迷わなくてすむと,あえて「-cookpad」オプションをつけてググって,クックパッドのレシピが検索結果に出ないようにする人まで出てきました.
そこで,この研究では,逆にレシピ数が膨大にあるという特徴を利用して,逆にユーザの好みにより近いレシピを容易に探せるようにします. 実際には,レシピの題名や内容から,作者がその料理の基本レシピに施したアレンジを表すアレンジ表現を自動または半自動で抽出します. そのアレンジ表現を手がかりに作成した教師データで学習した分類器で,「簡単」,「ヘルシー」,「和風」,「中華風」などのレシピの特徴を表すタグをレシピに付与して,レシピの検索・推薦時に好みのレシピだけを見れることを目指しています.
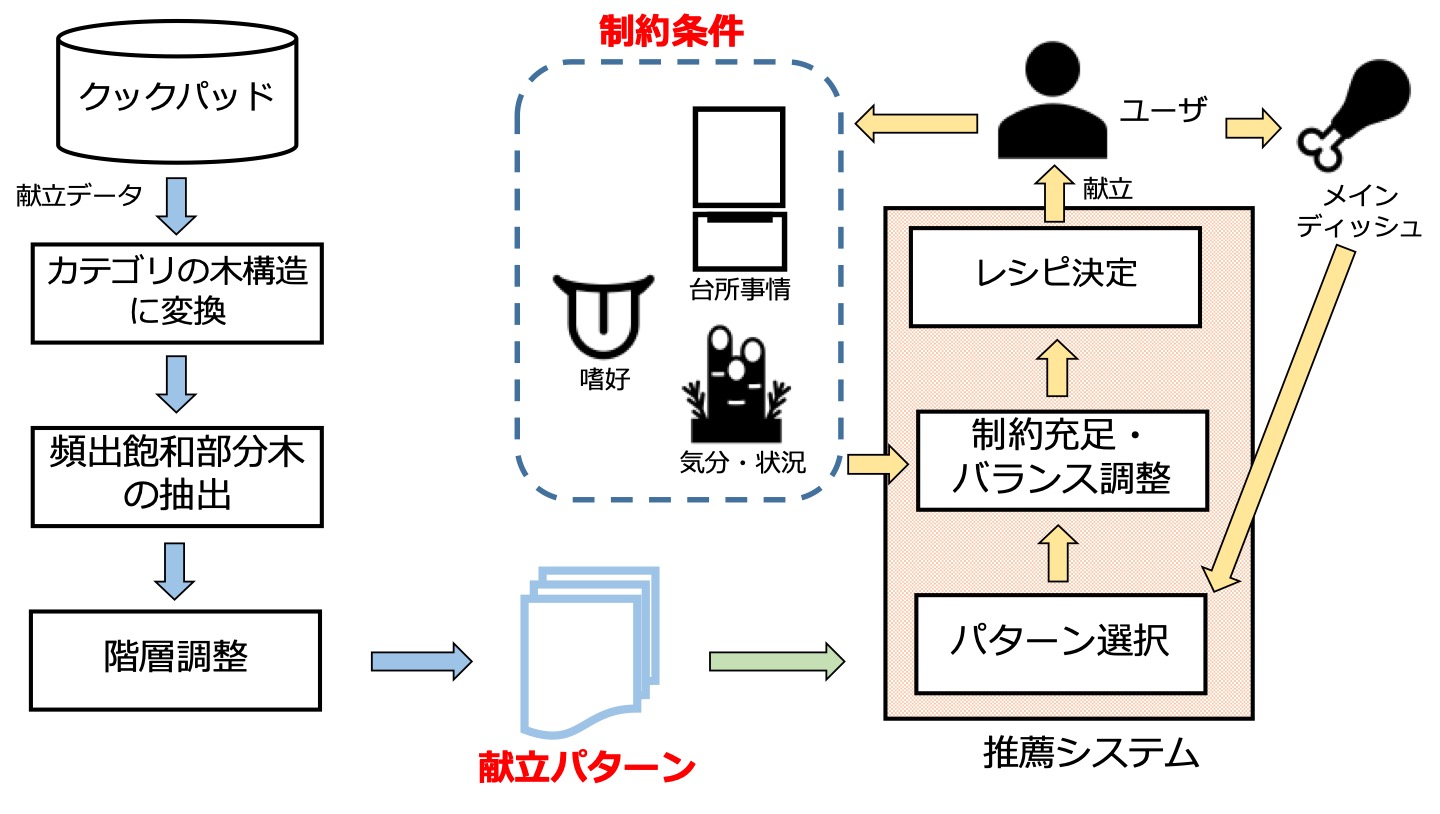
献立データのレシピカテゴリの組み合わせパターンによる献立推薦の概要図
クックパッドのようなユーザ投稿型レシピサイトが普及したことで,多彩なレシピが利用可能になったにも関わらず,日常生活で献立を考える負担はまったく解消されていません. その理由は,利用できるレシピ数が膨大すぎて逆に探すことが難しくなったうえに,また各家庭でレシピを組み合わせて献立として考えることを考慮していないことです. 例えば,クックパッドではレシピを組み合わせた献立も提供していますが,レシピ数に比べるとごくわずかしかないので,各家庭の好みや冷蔵庫の中の食材に合わせることはできません.
この研究では,少数の献立データから,明示的でない経験則に基づく料理の抽象的な組み合わせである献立パターンを抽出して,その献立パターンからユーザの制約条件(嗜好,気分・状況,台所事情)を考慮して,献立を作成します. 献立パターンの抽出には,頻出飽和アイテム集合を発見する宇野らのLCMアルゴリズムとクックパッドで用いているレシピのカテゴリ木構造を用いると共に,抽象度を統一するために抽出された頻出飽和部分木の階層調整をおこないます.
この研究は,IDRユーザフォーラム2019でクックパッド賞を受賞しました.
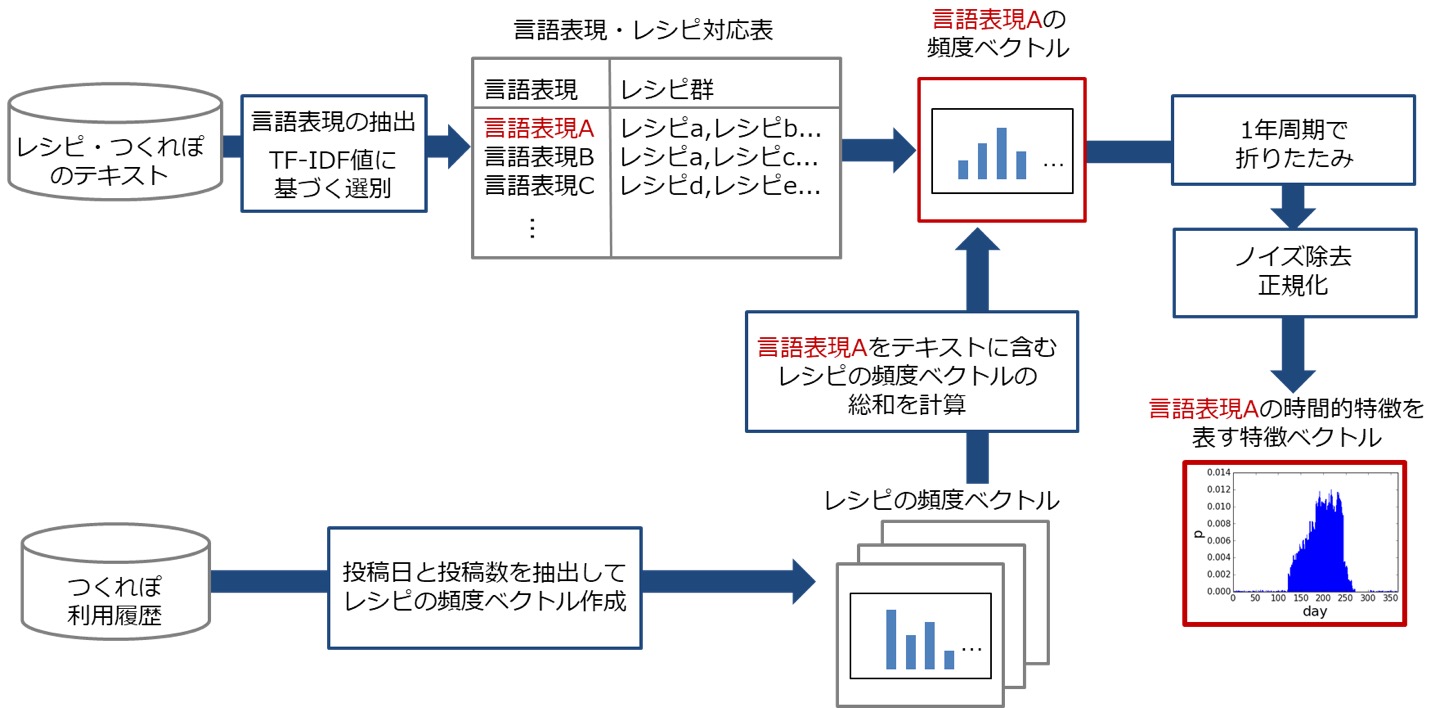
レシピと調理動機の時間的特徴によるレシピ検索の概要図
人間の生活は1日,1週間,1ヶ月,1年などの何らかの周期性を持つことが多く,それに食事を調理して食べるという日常的な行動も大きく影響されます. 例えば,夏には蕎麦や素麺などのさっぱりした料理が食べたくなりますが,冬は鍋料理が恋しくなります.また,正月,雛祭り,クリスマスなどの毎年のイベントには,特別な料理を作ります.
この研究では,「レシピを調理する」という人間の行動から,このような時間的特徴を自動的に抽出して,情報検索や推薦に利用できるようにします. 実際には,cookpadで公開されているレシピを調理したレポートである「つくれぽ」の数の頻度変化から,レシピ固有,さらに単語固有の時間的特徴を低次元のベクトルとして表現します. この特徴ベクトルを用いて,指定されたレシピまたは調理目的・特性を表すような単語(例,夏,クリスマス,花見など)に対して,季節や年中行事,あるいは定番料理のような,レシピが調理される時間的特徴が似ているレシピを発見します. なお,特に単語の場合には,ノイズを除去して特徴をより明確にするために,TF-IDFを用いてある単語がレシピで重要な役割を持たない場合を除外し,さらに音声処理で用いられるスペクトルサブストラクション法を用いて定常成分を除去しています.
この研究は,IDRユーザフォーラム2016優秀賞,DEIM 2017学生プレゼンテーション賞,データベース研究会+データ工学研究会+食メディア研究会・学生奨励賞を受賞し,情報処理学会論文誌:データベースに採録されました.
当研究室では,メインの3種類の研究テーマ以外にも,様々な分野に適用できる基礎的な研究や,実サービスを提供するような応用的な研究も行っています.
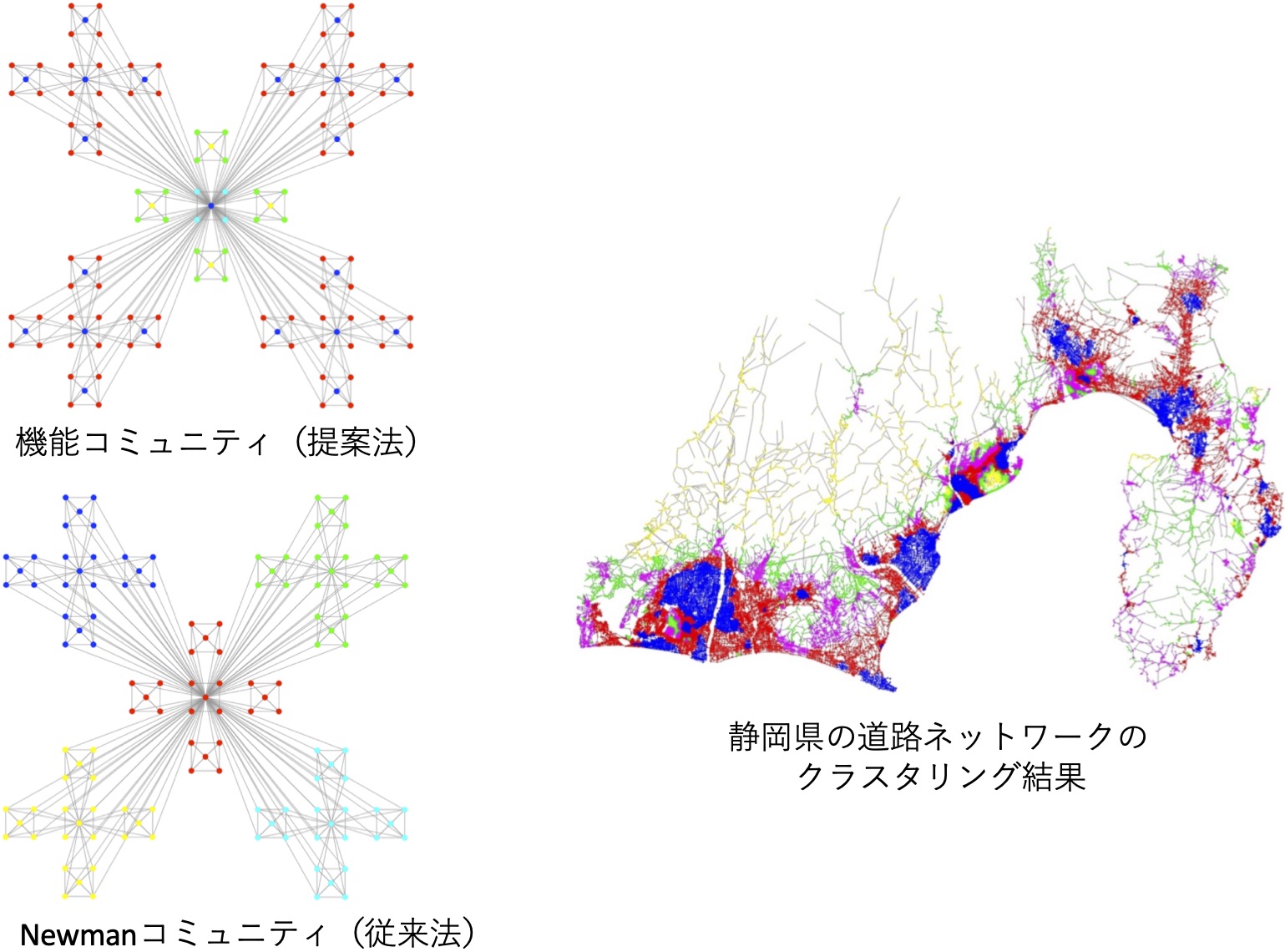
機能コミュニティの抽出例
インターネットの普及と共に,HTMLのハイパーリンクネットワークや,SNSのソーシャルネットワークなどの,現実のネットワーク構造データの入手が用意になると共に,そのデータの利用がサービスの質向上の重要な要素となってきました.
例えば,従来のNewman法のような近傍ノードをエッジの疎密からクラスタリングするアプローチに対して,機能コミュニティ抽出法では,同種の機能を持つと推定されるノード群をネットワーク構造全体からまとめて抽出します.
実際には,ノードが持つ機能性を,PageRankのスコアを貪欲法で繰り返し計算して求める場合の各ステップのスコアを持つ低次元ベクトルで表現します.これは,現在注目されているGraph Embeddingの先駆的なアプローチと言えます.
左の図は,まず機械的なネットワーク構造を機能コミュニティ法とNewman法でクラスタリングした場合の結果を示しています.さらに,低次数で疎密の差が小さい特徴を持つ空間ネットワーク(Spacial Network)もうまく処理でき,例えば静岡県の道路網は,都市地域,住宅地域,郊外地域に分離できます.
この研究は神奈川大学,東京工科大学,静岡県立大学との共同研究で,WebDB Forum 2011企業賞・ネクスト賞,WebDB Forum 2011優秀論文賞,2011年度DBSJ論文賞,WebDB Forum 2012企業賞・ミクシィ賞,WebDB Forum 2012優秀論文賞,第9回ネットワーク生態学シンポジウム ポスター優秀賞を受賞しました.
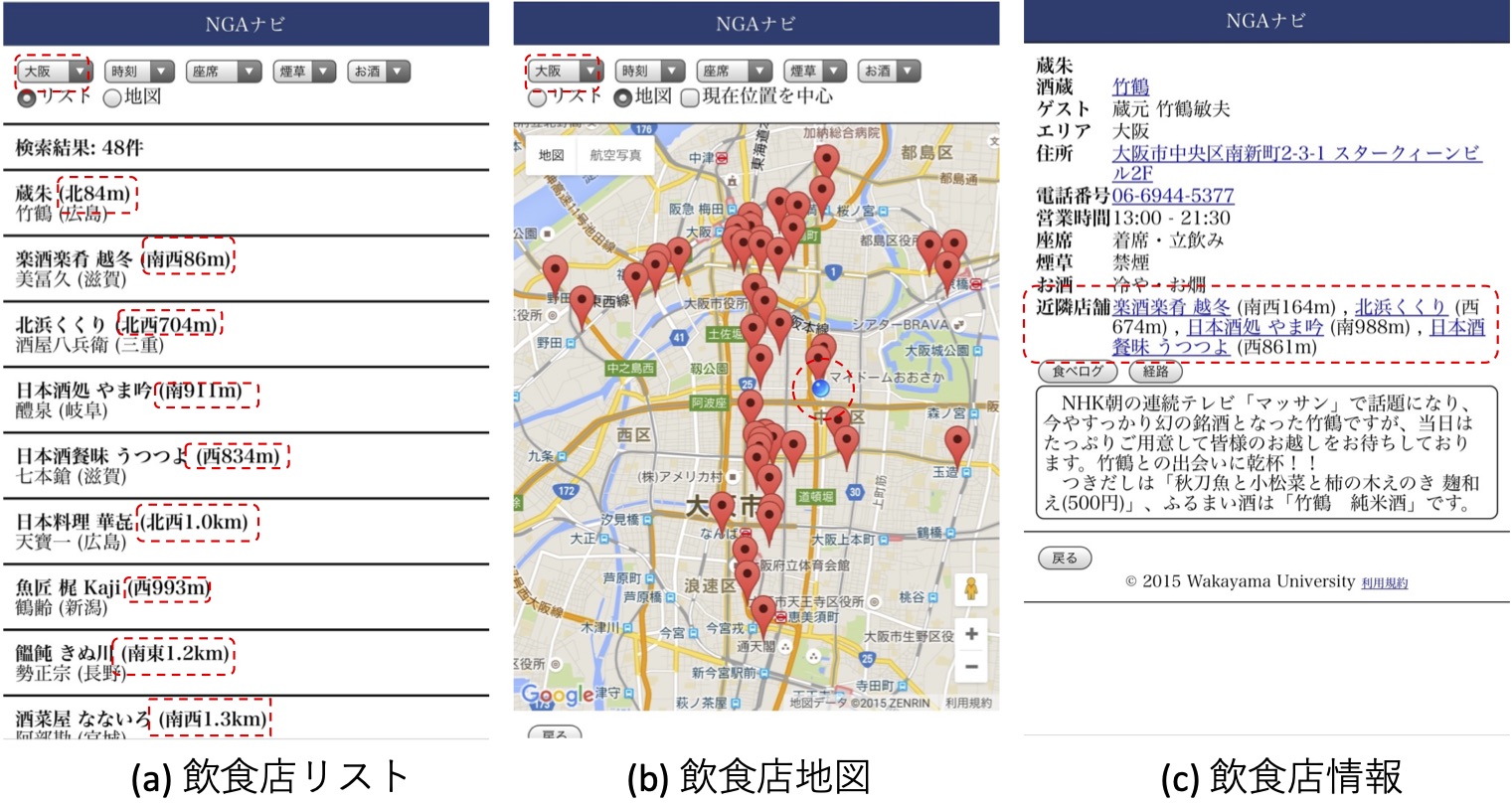
NGAナビの実行例
日本酒ゴーアラウンドは,日本酒卍固めが中心になって10月1日の「日本酒の日」に開催しているはしご酒イベントです. このイベントには多くの飲食店が参加するために,参加者は事前に公開される飲食店と酒蔵に関する情報を見てどのように飲み歩くかを計画したり,当日の混雑状況などによっては,その場で別の行きたいお店を探す必要があります.
そこで,当研究室では,2015年の日本酒ゴーアラウンド(NGA 2015)の参加飲食店・酒蔵の情報収集と当日の飲み歩き行動を支援するために「NGAナビ」(実行画面は左の図を参照)を作成して,数千人の参加者に実際に使ってもらいました.さらに,2015年9月24日からイベント当日の10月1日までの8日間の利用履歴とユーザの位置情報を,情報閲覧と回遊行動の観点から分析しました.
この研究は,ARG WI2研究会 第7回研究会萌芽研究賞を受賞しました.